This document contains guidance to help you avoid making mistakes when rating Search Ads tasks. The examples are similar to tasks rated in the past.
The rating is a two-step process:
According to GL 3.1. Query Type Question, we need to select the Query Type. To do so, we must determine whether the user had a particular app in mind or was searching for any app that meets their needs. Possible ratings are Navigational, Functional, Mixed, and Unclear.
Examples:
Query | Type | Explanation |
think dirty | Navigational | The user is looking for the Think Dirty app for retrieving cosmetics and personal care products information and comparisons. |
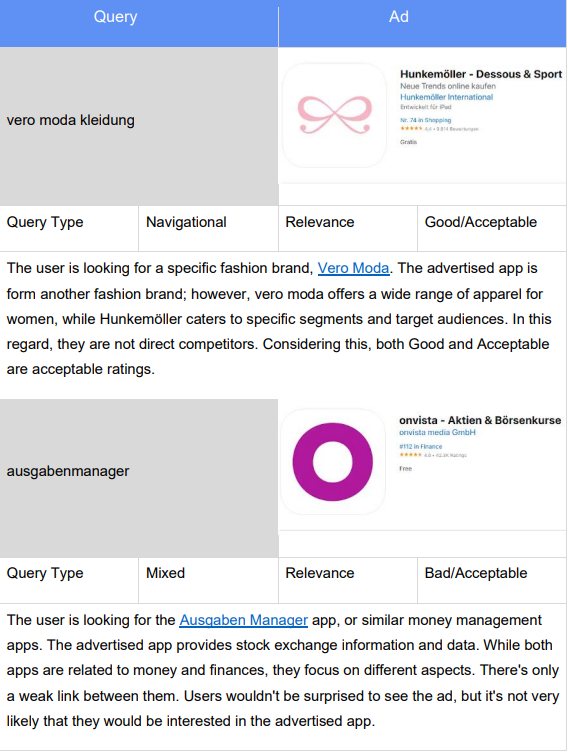
ausgabenmanager | Mixed | The user might be looking for the Ausgaben Manager app, or similar money management apps. |
tiktok analytics | Mixed | The user might be looking for the respective Tik Tok function, or the Tik Tok Analytics app, or similar apps providing insights into their Tik Tok account(s). |
In line with GL 4. Ad Relevance, after understanding the intent of the query, we rate the relevance of the returned ad. Relevance rating options are Excellent, Good, Acceptable, and Bad.
An Excellent ad features an app with a strong relationship to the query intent. Such apps are most likely of interest to the user.
A Good ad features an app somewhat related to the query intent. Users will be quite likely interested in the app, but other apps might be more compelling.
An Acceptable ad features an app that is only slightly related to the query intent. Users would not be surprised to see the ad, but will rather not be too interested in the app.
A Bad ad features an app that is entirely unrelated to the query intent. It might surprise the user and could be detrimental to the user experience.
Examples: